Since Llama3 was released, the PyTorch llama3 documentation has a few glitches pointing at configurations in torchtune that are still referencing Llama2. The meta website is a little more up-to-date, but the documentation is a little light on details. So, I wrote this article to bring everything together.
Prerequisites
- You’ll want to use Python 3.11 until Torch compile supports Python 3.12 , and I recommend setting up a virtual environment for this using
venvorpipenv. - Install torchtune
pip install torchtune
- Install EleutherAI’s Evaluation Harness
pip install lm_eval==0.4.*
Download Llama3-8B model
You will need to get access to Llama3 via instructions on the official Meta Llama3 page. You will also need your Hugging Face token setup from here.
Note: some examples here reference “checkpoint-directory”. This will be the directory where your downloaded model weights are stored. In the following examples we’ll use /tmp/Meta-Llama-3-8B for the checkpoint directory.
|
|
Fine-tune the model
The out-of-the-box recipe for torchtune single-GPU script tuning uses the Stanford Alpaca dataset, which has 52K instruction-following prompt pairs. It’s worth looking this over if you want to provide your own data, but for now, we’ll use the default recipe.
Get some coffee. This process will take, depending on your GPU, at least a couple of hours on a single-GPU. I’m running a 24GB NVIDIA RTX 4090, and this process took three hours.
With less VRAM and a lighter-weight GPU, this could take up to 16 hours or more. There are instructions on the Meta Llama3, and the Llama3 PyTorch torchtune site that discuss running on multiple-GPU systems and tuning for smaller GPUs.
|
|
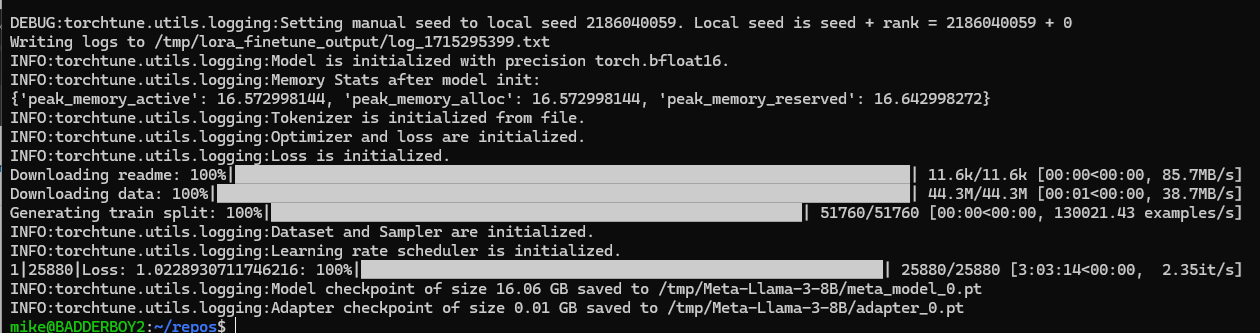
Tuning run results
When completed, the above command will place meta_model_0.pt and adapter_0.pt files in the checkpoint directory.
Evaluating the tuned model
To run evaluations, you can use torchtune to make copies of the various elleuther_evaluation config files, then edit them to reflect where to look for models and which merics to run.
For example
tune cp eleuther_evaluation ./custom_eval_config.yaml
However, the instructions I found on the PyTorch end-to-end workflow needed fixing, so I have provided already edited copies of these files for our use here.
Baseline Evaluation of Un-tuned Llama3-8B
custom_eval_config_orig.yaml
# Config for EleutherEvalRecipe in eleuther_eval.py
#
# To launch, run the following command from root torchtune directory:
# tune run eleuther_eval --config eleuther_evaluation tasks=["truthfulqa_mc2","hellaswag"]
# Model Arguments
model:
_component_: torchtune.models.llama3.llama3_8b
checkpointer:
_component_: torchtune.utils.FullModelMetaCheckpointer
checkpoint_dir: /tmp/Meta-Llama-3-8B/original
checkpoint_files: [
consolidated.00.pth
]
recipe_checkpoint: null
output_dir: /tmp/Meta-Llama-3-8B/original
model_type: LLAMA3
# Tokenizer
tokenizer:
_component_: torchtune.models.llama3.llama3_tokenizer
path: /tmp/Meta-Llama-3-8B/original/tokenizer.model
# Environment
device: cuda
dtype: bf16
seed: 217
# EleutherAI specific eval args
tasks: ["truthfulqa_mc2"]
limit: null
max_seq_length: 4096
# Quantization specific args
quantizer: null
Run
tune run eleuther_eval --config ./custom_eval_config_orig.yaml
On the 24GB RTX 4090 this takes about four minutes, and the output looks like this. We get about 43.9% accuracy.

Fine-Tuned Llama 8B Evaluation
custom_eval_config.yaml
# Config for EleutherEvalRecipe in eleuther_eval.py
#
# To launch, run the following command from root torchtune directory:
# tune run eleuther_eval --config eleuther_evaluation tasks=["truthfulqa_mc2","hellaswag"]
# Model Arguments
model:
_component_: torchtune.models.llama3.llama3_8b
checkpointer:
_component_: torchtune.utils.FullModelMetaCheckpointer
checkpoint_dir: /tmp/Meta-Llama-3-8B
checkpoint_files: [
meta_model_0.pt
]
recipe_checkpoint: null
output_dir: /tmp/Meta-Llama-3-8B
model_type: LLAMA3
# Tokenizer
tokenizer:
_component_: torchtune.models.llama3.llama3_tokenizer
path: /tmp/Meta-Llama-3-8B/original/tokenizer.model
# Environment
device: cuda
dtype: bf16
seed: 217
# EleutherAI specific eval args
tasks: ["truthfulqa_mc2"]
limit: null
max_seq_length: 4096
# Quantization specific args
quantizer: null
Note in the above config we are now pointing at the location of the fine-tuned weights meta_model_0.pt
Run
tune run eleuther_eval --config ./custom_eval_config.yaml
The output looks like this. We get 55.3% accuracy. An increase of about 11.4%!

Model Generation
Now for the fun part. Seeing how the fine-tuned model handles prompts.
We will use a top_k=300 and a temperature=0.6 for these tests. I noticed that temperature=0.8 definitely produces hallucinatory output.
Fine-tuned Llama-8B Generation
custom_generation_config.yaml
# Config for EleutherEvalRecipe in eleuther_eval.py
#
# To launch, run the following command from root torchtune directory:
# tune run eleuther_eval --config eleuther_evaluation tasks=["truthfulqa_mc2","hellaswag"]
# Model Arguments
model:
_component_: torchtune.models.llama3.llama3_8b
checkpointer:
_component_: torchtune.utils.FullModelMetaCheckpointer
checkpoint_dir: /tmp/Meta-Llama-3-8B
checkpoint_files: [
meta_model_0.pt
]
recipe_checkpoint: null
output_dir: /tmp/Meta-Llama-3-8B
model_type: LLAMA3
# Tokenizer
tokenizer:
_component_: torchtune.models.llama3.llama3_tokenizer
path: /tmp/Meta-Llama-3-8B/original/tokenizer.model
# Environment
device: cuda
dtype: bf16
seed: 217
# Quantization specific args
quantizer: null
# Generation arguments; defaults taken from gpt-fast
# prompt: "Hello, my name is"
max_new_tokens: 600
temperature: 0.6 # 0.8 and 0.6 are popular values to try
top_k: 300
Run
tune run generate --config ./custom_generation_config.yaml \
prompt="What are some interesting sites to visit in the Bay Area?"
So, this works, but we still have to load up 16GB worth of weights and run inference, which takes about 60 seconds on my rig. Your mileage may vary. Let’s see if we can “quantize” our weights to speed up load time, and the inference time.
Quantization
Quantizing the model weights involves reducing the weights to smaller integer types. There are many algorithms, but we will use one of the standard torchtune recipes using TORCHAO to produce an ‘INT4’ quantization.
INT4 config
custom_quantization_config.yaml
# Config for EleutherEvalRecipe in eleuther_eval.py
#
# To launch, run the following command from root torchtune directory:
# tune run eleuther_eval --config eleuther_evaluation tasks=["truthfulqa_mc2","hellaswag"]
# Model Arguments
model:
_component_: torchtune.models.llama3.llama3_8b
checkpointer:
_component_: torchtune.utils.FullModelMetaCheckpointer
checkpoint_dir: /tmp/Meta-Llama-3-8B
checkpoint_files: [
meta_model_0.pt
]
recipe_checkpoint: null
output_dir: /tmp/Meta-Llama-3-8B
model_type: LLAMA3
# Tokenizer
tokenizer:
_component_: torchtune.models.llama3.llama3_tokenizer
path: /tmp/Meta-Llama-3-8B/original/tokenizer.model
# Environment
device: cuda
dtype: bf16
seed: 217
quantizer:
_component_: torchtune.utils.quantization.Int4WeightOnlyQuantizer
groupsize: 256
Run
tune run quantize --config ./custom_quantization_config.yaml
This runs fairly quickly, producing a meta_model_0-4w.pt weights file of only 4.92GB in the checkpoint directory.

Generation using the quantized model
OK! Let’s see how much faster we can run things, but keep in mind that the INT4 version of the weights will reduce the model’s language performance somewhat.
Quantized generation configuration
custom_generation_4w_config.yaml
# Config for EleutherEvalRecipe in eleuther_eval.py
#
# To launch, run the following command from root torchtune directory:
# tune run eleuther_eval --config eleuther_evaluation tasks=["truthfulqa_mc2","hellaswag"]
# Model Arguments
model:
_component_: torchtune.models.llama3.llama3_8b
checkpointer:
_component_: torchtune.utils.FullModelTorchTuneCheckpointer
checkpoint_dir: /tmp/Meta-Llama-3-8B
checkpoint_files: [
meta_model_0-4w.pt
]
recipe_checkpoint: null
output_dir: /tmp/Meta-Llama-3-8B
model_type: LLAMA3
# Tokenizer
tokenizer:
_component_: torchtune.models.llama3.llama3_tokenizer
path: /tmp/Meta-Llama-3-8B/original/tokenizer.model
# Environment
device: cuda
dtype: bf16
seed: 217
# Quantization specific args
quantizer:
_component_: torchtune.utils.quantization.Int4WeightOnlyQuantizer
groupsize: 256
# Generation arguments; defaults taken from gpt-fast
# prompt: "Hello, my name is"
max_new_tokens: 600
temperature: 0.6 # 0.8 and 0.6 are popular values to try
top_k: 300
Note there are some key differences in this generation configuration file with the non-quantized generation file we used earlier on the fine-tuned model. Namely, we are pointing at the meta_model_0-4w.pt weights now. Also, we must provide the quantizer details matching the ones we used in the quantization step.
Run
tune run generate --config ./custom_generation_4w_config.yaml \
prompt="What are some interesting sites to visit in the Bay Area?"
Here is what I got
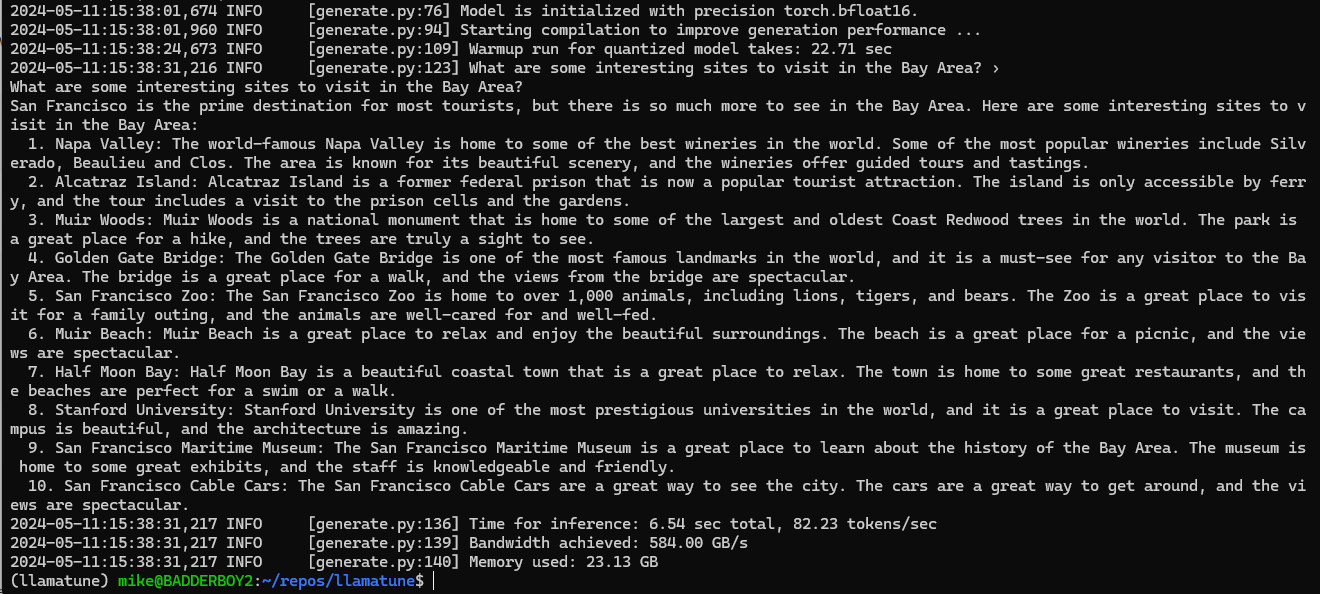
It takes about 22 seconds to load up the model, and a mere 7 seconds to run the inference. This is about a 300% improvement over the un-quantized generation run, and the output also looks pretty good.
However, let’s see if we can evaluate this quantized model’s performance on instruction following to see if the quantization has affected the accuracy of the model.
Quantized evaluation configuration
custom_eval_4w_config.yaml
# Config for EleutherEvalRecipe in eleuther_eval.py
#
# To launch, run the following command from root torchtune directory:
# tune run eleuther_eval --config eleuther_evaluation tasks=["truthfulqa_mc2","hellaswag"]
# Model Arguments
model:
_component_: torchtune.models.llama3.llama3_8b
checkpointer:
_component_: torchtune.utils.FullModelTorchTuneCheckpointer
checkpoint_dir: /tmp/Meta-Llama-3-8B
checkpoint_files: [
meta_model_0-4w.pt
]
recipe_checkpoint: null
output_dir: /tmp/Meta-Llama-3-8B
model_type: LLAMA3
# Tokenizer
tokenizer:
_component_: torchtune.models.llama3.llama3_tokenizer
path: /tmp/Meta-Llama-3-8B/original/tokenizer.model
# Environment
device: cuda
dtype: bf16
seed: 217
# EleutherAI specific eval args
tasks: ["truthfulqa_mc2"]
limit: null
max_seq_length: 4096
# Quantization specific args
quantizer:
_component_: torchtune.utils.quantization.Int4WeightOnlyQuantizer
groupsize: 256
Note in the above config we have changed the checkpointer to FullModelTorchTuneCheckpointer, as this checkpointer can support the weights_only=true checkpoint file we created with the Int4WeightOnlyQuantizer when we quantized the model. We have also added the quantizer details.
Run
tune run eleuther_eval --config ./custom_eval_4w_config.yaml
Here are the results showing we got an accuracy of 49% with the quantized, fine-tuned, model. This is a net increase of 5% over the baseline non-finetuned Llama3 model. By quantizing, we “took back” about 6% of the accuracy we gained in the fine-tuning of the model.
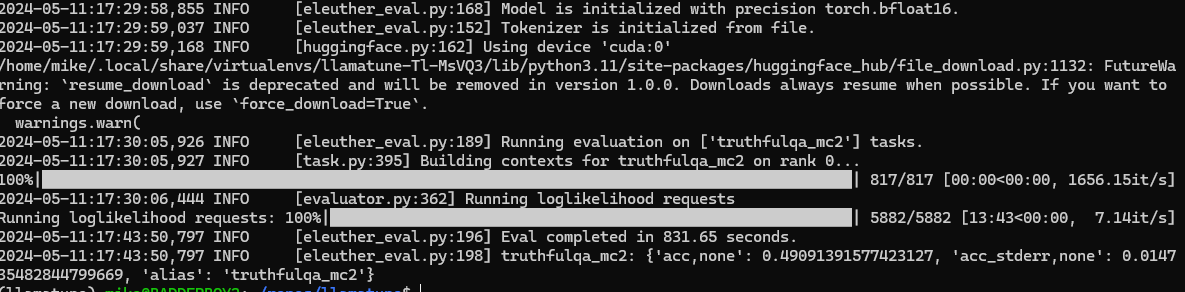
So, we traded some accuracy for performance, but we still ended up with an overall improvement. This shows the importance of adding evaluation benchmarking when fine-tuning LLM models.
We Made It!
If you followed along this far, congratulations 🎉!
I hope you had as much fun as I did. Next, I’ll cover how to encode this smaller model into GGUF format and post it to a Huggingface repository to share with others.