An increasing number of open-sourced generative AI large language models (LLM) are being hosted behind an OpenAI API-compatible endpoint or have tools that offer an OpenAI API. The Python library for accessing OpenAI is just a REST client, and the library provides a way to specify the URL and an API key, as well as the model being offered by the provider.
Here are a few examples of how the OpenAI library is used with other open-source models.
Ollama
Although there are macOS and Windows versions, Ollama is primarily a Linux-based tool that lets you download various LLMs easily and host them on your own hardware. An impressive number of models are available. Ollama runs locally as an API by default that accepts REST commands compatible with the OpenAI API.
See the Ollama GitHub repository.
Here’s a quick start to run a small LLM model locally. If you have an Nvidia or AMD GPU, it will configure itself to use them automatically. If not, it defaults to CPU.
Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
Manual GGUF model creation procedure
The following steps show how to install a GGUF model file into Ollama. This is useful in cases where the model may not already be in the Ollama Hub list of models. It also tends to work well in cases where you are behind a proxy that is causing problems using the ollama run <model> command.
You will need the HuggingFace CLI to download the Phi-2 LLM model manually.
python3 -m pip install huggingface-cli
Download the LLM model in GGUF format. Note: make sure to have your HF_TOKEN from here setup as an enviroment variable, or run huggingface-cli login prior to this.
# If run from your home directory, this creates a ~/downloads directory if not already existing:
huggingface-cli download \
TheBloke/phi-2-GGUF \
phi-2.Q4_K_M.gguf \
--local-dir downloads \
--local-dir-use-symlinks False
Create a file named Modelfile (actually, any name is OK) with the following line in it.
FROM ./downloads/phi-2.Q4_K_M.gguf
Build the model using this file as input to Ollama create:
ollama create phi2 -f Modelfile
Now you can verify the model is present, then run it:
ollama list
ollama run phi2
>>> in a sentence, why is the sky blue?
The sky is blue because of a phenomenon known as Rayleigh scattering....
The response on my Surface with i7-1185G7 @ 3.00GHZ CPU (no GPU) takes about 30 seconds.
By comparison, my RTX4090-equipped Corsair Vengeance i7400 liquid-cooled i9 12900X 64GB RAM box runs the Llama7 8B Model for the same query about the sky in less than a second.
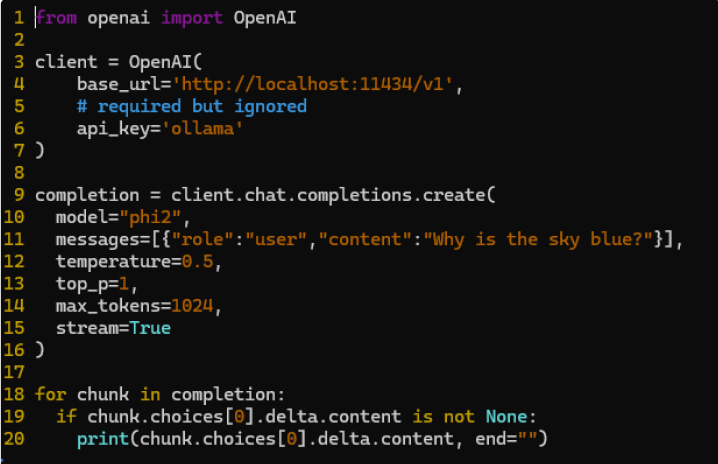
Here is an example of running a query using the OpenAI library against the local Ollama API referencing the PHI-2 model we loaded above. In the case of Ollama, there is no api_key, but it is a required element for the library.
Nvidia
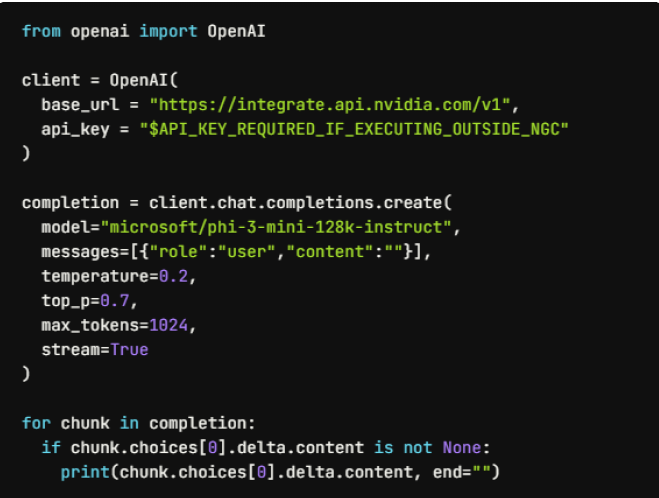
Nvidia provides access to open-source foundation models on its build platform (build.nvidia.com/explore/discover), which makes it easy to try these. Example code for these models uses an OpenAI API-compatible method. This is not an OpenAI-hosted model. It uses the same OpenAI Python library as the Ollama example above except, in this case, NVidia does have a process for requesting and using an API_KEY that works with their playground host. In this example, the phi-3 model is being requested.
Open-source models will increasingly be represented in cases where large models are overkill or the desire for complete control over the data is paramount. Containerizing these and running them on cloud infrastructure or running them locally with your own data on your own hardware is within reach of modest budgets and is a good way to learn more about LLMs and the tools used to develop solutions with them.